


INTRODUCTION
Data scientists frequently devote the majority of their time to the technical aspects of the "21st Century's Most Sexy Job." For every 100 data scientists working on any project, at least 90 would be concerned with what languages to use, frameworks to adore, models to experiment with, projects to become involved with, and computational power issues. This leaves us with a small group of ten with no idea where to begin - " were you expecting these ten to be the chosen ones? No, it is concerning that data scientists, particularly newcomers, pay little attention to domain knowledge."
EYE OPENER
I was a member of the old 90 until my team was dealt with during a hackathon hosted by 'Analytical Vidhya.' This hackathon project was a ‘football analysis and a predicting project’. We were tasked with processing this club's (name withheld for security reasons) extremely complex football data and developing a model that could decompose player performances into main objective elements, thereby assisting the club in gaining a competitive advantage over its competitors. This was a fantastic project that taught us a lot; I'll be writing about it soon.
The takeaway here is that we had done everything we could, optimized and trained multiple models multiple times, and kept pushing limits to improve our score. We didn't try feature engineering until near the end of the event. But, with our below-average football domain knowledge, there was little we could do about it. Using the Data Science Life Cycle as a guide and two real-life case studies for comparison, I attempted to demonstrate the importance of domain knowledge in a data science project in this article.
First, let us refresh our minds on what domain knowledge and data science processes imply, and then try to understand the relationship between domain knowledge and the phases in a typical data science process.
DOMAIN KNOWLEDGE
Domain knowledge in data science refers to general background knowledge of the field or environment to which data science is applied. Data science as a discipline is the study of tools used to model data, generate insights from data, and make data-driven decisions. They are generic tools that are used in a variety of fields, including engineering, law, medicine, and finance. Domain knowledge is more focused. The lack of domain knowledge makes applying appropriate methods and assessing their performances difficult. For domain knowledge to be effective, it must be applied throughout the data science process.
DATA SCIENCE PROCESS
The data science process is a methodical approach to problem-solving with data. It offers a structured framework for articulating data problems as questions, determining how to solve them, and then presenting the solutions to stakeholders.
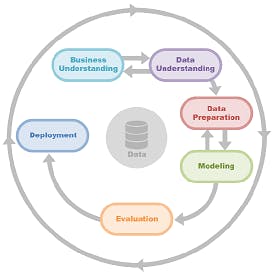 CRISP-DM image
CRISP-DM image
CRISP-DM is an acronym that stands for Cross Industry Standard Process for Data Mining. It is a popular industry-standard methodology and process model because it is flexible and customizable. It is also a tried-and-true method for guiding data mining projects.
Business Understanding - The first step in the CRISP-DM process clarifies the goals of the business and focuses on the data science project. This phase, which includes domain knowledge, begins with a generic problem description and includes defining desired performance criteria. Defining the goals entails more than just identifying the metrics to change. For a simple problem like predicting credit default, where the problem definition is simply predicting the probability of default based on data from previous borrowers, defining the problem is an easy step. Consider, on the other hand, robotics, medicine, or entertainment problem in which a person with no domain knowledge cannot even define the patterns to see in the data.
Data Understanding - Understanding your data is the next step in CRISP-DM. In this phase, you'll figure out the available data, where you can get more of it, what your data contains, and how good it is. You'll also need to decide which data collection tools to use and how to collect your initial data. Then you'll describe the initial data's properties, such as the format, quantity, and records or fields in your data sets. Only a data scientist with sufficient domain knowledge can clearly understand the type and properties of required data without wasting time and resources.
Data Preparation - Data is obtained from multiple sources and is usually unusable in its raw form due to corrupt and missing attributes, conflicting values, and outliers. Resolving these issues improves data quality, allowing it to be used effectively in the modeling stage. Data cleaning and feature engineering are two methods for preparing data for modeling. Data cleaning and feature engineering both require data transformation. Incorrectly transformed data can produce erroneous results. Furthermore, domain knowledge is essential when selecting the best features from the data to provide the most predictive power.
Modeling - There are numerous data modeling options. You will select the best based on business objectives, variables, tools, etc. The model created here addresses the issues identified in the first step. The selection of a suitable model is critical to the success of the data science process. Again, this depends on the field of application and is supported by extensive domain knowledge.
Evaluation - During the evaluation phase, you will evaluate the model based on your company's goals. Then you'll iterate over your work process again, explaining how your model will help, summarizing your findings, and making necessary changes. Domain knowledge drives the selection of performance metrics and thresholds. Only a data scientist with domain knowledge can accurately estimate the costs of model failure.
Deployment - Although deployment is the final phase of the CRISP-DM methodology, it is not the end of your project. You will plan and document how you intend to deploy the model, and how the results will be delivered, during the deployment phase. You'll also need to monitor the results and keep the model up to date. Sufficient domain knowledge informs you of the best way(s) to put the chosen algorithm into production. Domain knowledge is also essential for post-deployment activities such as monitoring and iterating.
HOW DOMAIN KNOWLEDGE INTERCEPTS THE DATA SCIENCE PROCESSES OF CRISP-DM
In this section, I'll go over how domain knowledge applies to each step of the data science process. In addition, I would create real-world scenarios using two different data science projects from my two favorite industries.
CASE STUDY 1: Patient Identification for Clinical Trials (DATA SCIENCE IN HEALTHCARE).
Business Understanding: what type of clinical trial (pilot or feasibility studies, prevention, screening, or treatment trials, etc.), what do we hope to gain from using data science in this clinical trial analysis (predicting clinical trial outcomes, side effects to medications, or even drug-drug interaction), who is eligible to participate, what the protocol entails, what the risks, benefits, and evaluation metrics are.
Data Understanding: Clinical trial accuracy is influenced by physician-based factors (such as academic versus community settings, oncologic specialty, personal bias), patient-based factors (such as age, gender, racial profile, performance status), and socioeconomic status. For quality assurance, data collection would aim to collect information on the majority of the aforementioned factors.
Data Preparation: Clinical Data Management (CDM) is critical for clinical trial projects, as it leads to the generation of high-quality, reliable, and statistically sound data. At regular intervals during a trial, CDM procedures such as Case Report Form (CRF) design, CRF annotation, database design, data entry, data validation, discrepancy management, medical coding, data extraction, and database locking are evaluated for quality.
Modeling: natural language processing and exploratory data analysis of patient records to identify suitable patients for clinical trials and patients with distinct symptoms, examine interactions of specific biomarkers in potential trial members, and predict drug interactions and side effects to avoid complications.
Evaluation: Because this project and field are so sensitive, metrics like speed and accuracy are critical. Concurrently, the model must perform exceptionally well. A threshold in the age group with a precise record could serve as a baseline for accuracy. This is all dependent on the type of clinical trial test in progress. Data blinding, hyperparameter optimizations, and other techniques ensure that algorithms are optimized and accurate for deployment.
Deployment: a platform connecting data scientists, clinicians, academic researchers, and pharmaceutical companies to unlock medical insights from siloed, multimodal datasets. To match patients and trials accurately. An oncology studies platform that clinicians at institutions around the world can use to diagnose cancer and conduct clinical trials to understand how patients will respond to treatment, and provide real-time monitoring of patient dosing and behavior to enable smaller and faster trials.
CASE STUDY 2: Using Recommendation Systems to Personalize Content (DATA SCIENCE IN ENTERTAINMENT).
- Business Understanding: recommend the most relevant items or contents to increase the company's revenue. Suggestions will base on user behavior and history, like information on previous preferences.
Data Understanding: data collected may be implicit or explicit depending on the model in use. Implicit data is information gathered from activities such as web searches, song or video watch history, clicks, cart events, search logs, and order history. Customer reviews and ratings, likes and dislikes, and product comments are examples of explicit data. A project could also use customer attribute data such as demographics (age, gender), psychographics (interests, values), and feature data to identify similar customers and to determine product similarity (genre, item type).
Data Preparation: Before data can be used, it must be drilled down and prepared. There are numerous methods for processing data. Real-time analysis entails processing data as it is collected. When data is not needed immediately, batch analysis (data is processed regularly) and near-real-time analysis (data is processed in minutes rather than seconds) is used.
Modeling: can be collaborative, content-based, a combination of the two, or personalized filtering. The type of filtering (model) used is determined by the project goals, the success baseline, and the available data.
Evaluation: metrics for recommender systems include predictive accuracy metrics, classification accuracy metrics, rank accuracy metrics, and non-accuracy metrics.
Deployment: this may entail deploying as a mobile or website application. It may also become a REST API for integration.
CONCLUSION
Using the examples above, we can see that terminologies, techniques, and baselines differ in almost every phase of a data science project. The presence of domain experts as data scientists or on the data science team is critical to the success of any data science project. A financial project's success or failure criteria differ from those used in medicine. As more businesses enter the world of data, IoT, and the cloud, the value of data scientists with specialties becomes clearer. It is impossible to be a domain expert in all aspects of data. The truth is that data scientists must prepare for the numerous industries that are now adopting data-driven practices. This emphasizes the importance of domain knowledge in data science more than ever.
I sincerely hope that after reading this piece, you understand how critical domain knowledge is in a data science project. I recommend hiring data scientists with sufficient domain knowledge and proven work in the project field for companies and start-ups. To every data scientist who has taken the time to read this, I encourage you to experiment with specialization and see how efficient you become.
I am open to comments, opinions, additions and subtractions. Feel free to engage. Adios!!
REFERENCES
Sakshi Gupta (2022, May 16). Data Science Process: A Beginner’s Guide in Plain English Springboard, SpringBoard. Retrieved from springboard.com/blog/data-science/data-scie..
CFI Team (2022, January 15). Domain Knowledge (Data Science), Corporate Financial Institute (CFI). Retrieved from corporatefinanceinstitute.com/resources/kno..
Jami (2019, November 25). The Role of Domain Knowledge in Data Science, Empirical Data. Retrieved from empiricaldata.org/dataladyblog/the-role-of-..
Johnny Lance (2022, June 20). 10 Real-World Data Science Case Studies Projects with Example, Project Pro. Retrieved from projectpro.io/article/data-science-case-stu..
Jennifer K Logan, Chad Tang, Zhongxing Liao, et al. An Analysis of Factors Affecting Successful Clinical Trial Enrollment in the Context of Three Prospective Randomized Control Trials. Int J Radiat Oncol Biol Phys. 2017;97(4):770-777. [PubMed]
Luke Delixton (2021, May 31). Things to Consider About Clinical Trials, Closer Look at Stem Cells. Retrieved from closerlookatstemcells.org/from-lab-to-you/t..
Ajitesh Kumar (2021, October 8). Clinical Trials & Predictive Analytics Use Cases, VitalFlux. Retrieved from vitalflux.com/clinical-trials-predictive-an..
Binny Krishnankutty, Shantala Bellary, Naveen B.R. Kumar, et al. Data management in clinical research: An overview. Indian J Pharmacol. 2012 Mar-Apr; 44(2): 168–172. [PubMed]
Kezia Parkins (2021, July 29). Five AI-enhanced clinical trial start-ups to watch in 2021, Clinical Trials Arena. Retrieved from clinicaltrialsarena.com/analysis/five-ai-en..
Elena Bondarik (2019, May 7). Recommender Systems for Digital Businesses: Which Is Best?, Dataversity. Retrieved from dataversity.net/recommender-systems-for-dig..
Vijaysinh Lendave (2021, October 24). How to Measure the Success of a Recommendation System?, Analytics India Mag. Retrieved from analyticsindiamag.com/how-to-measure-the-su...